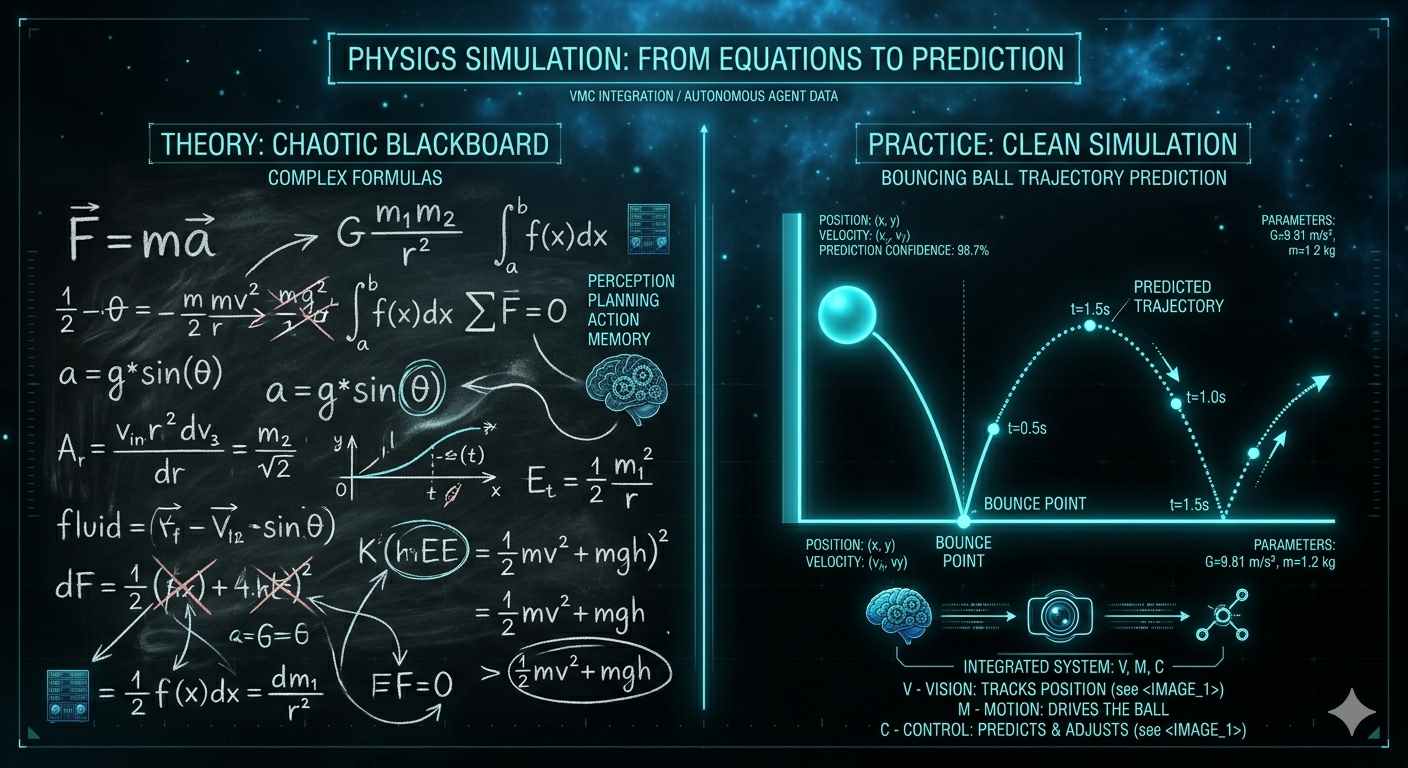
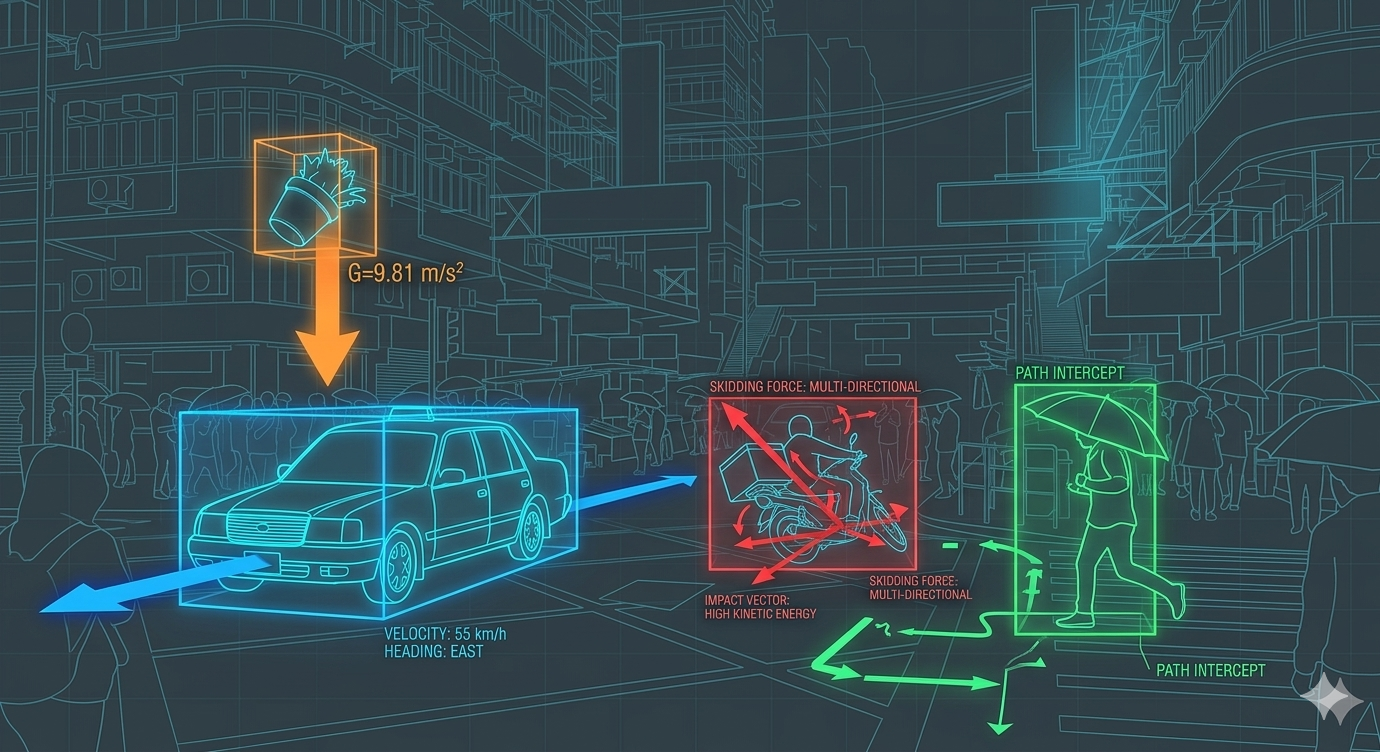
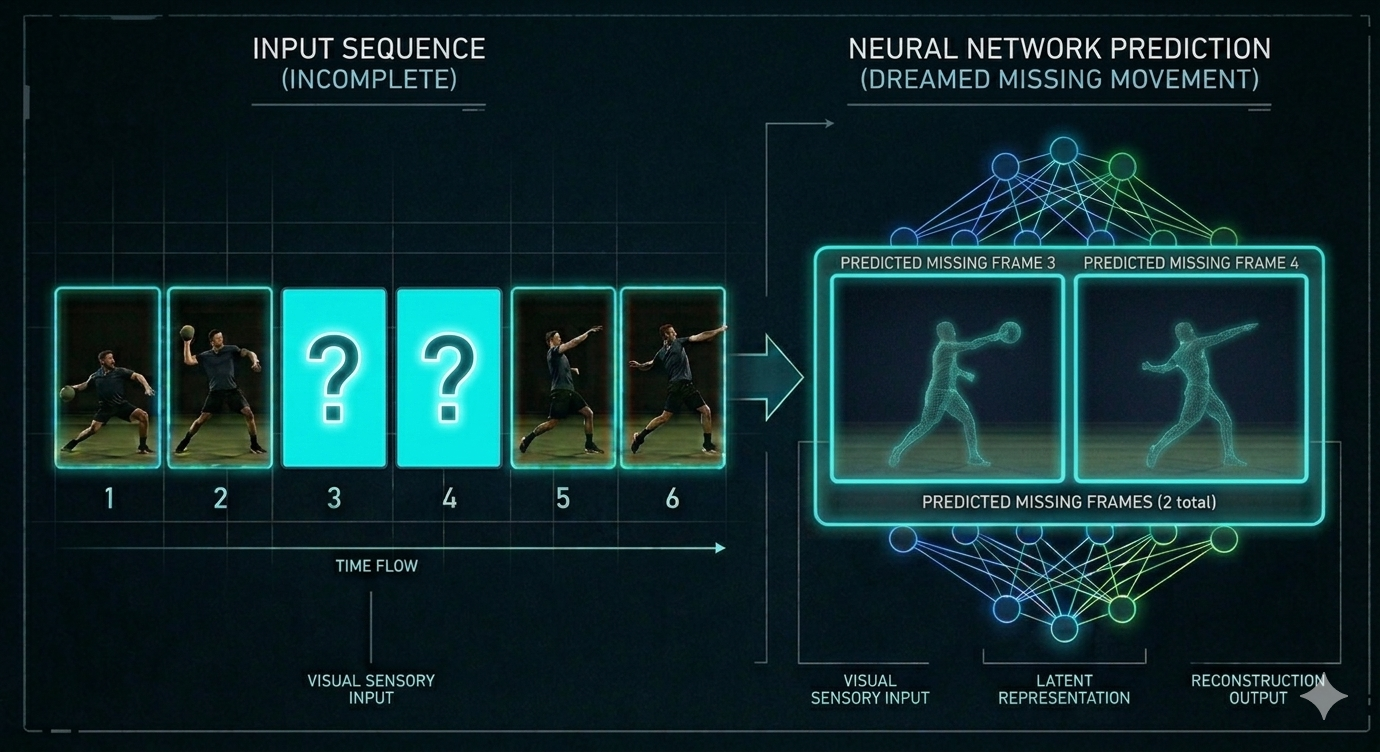
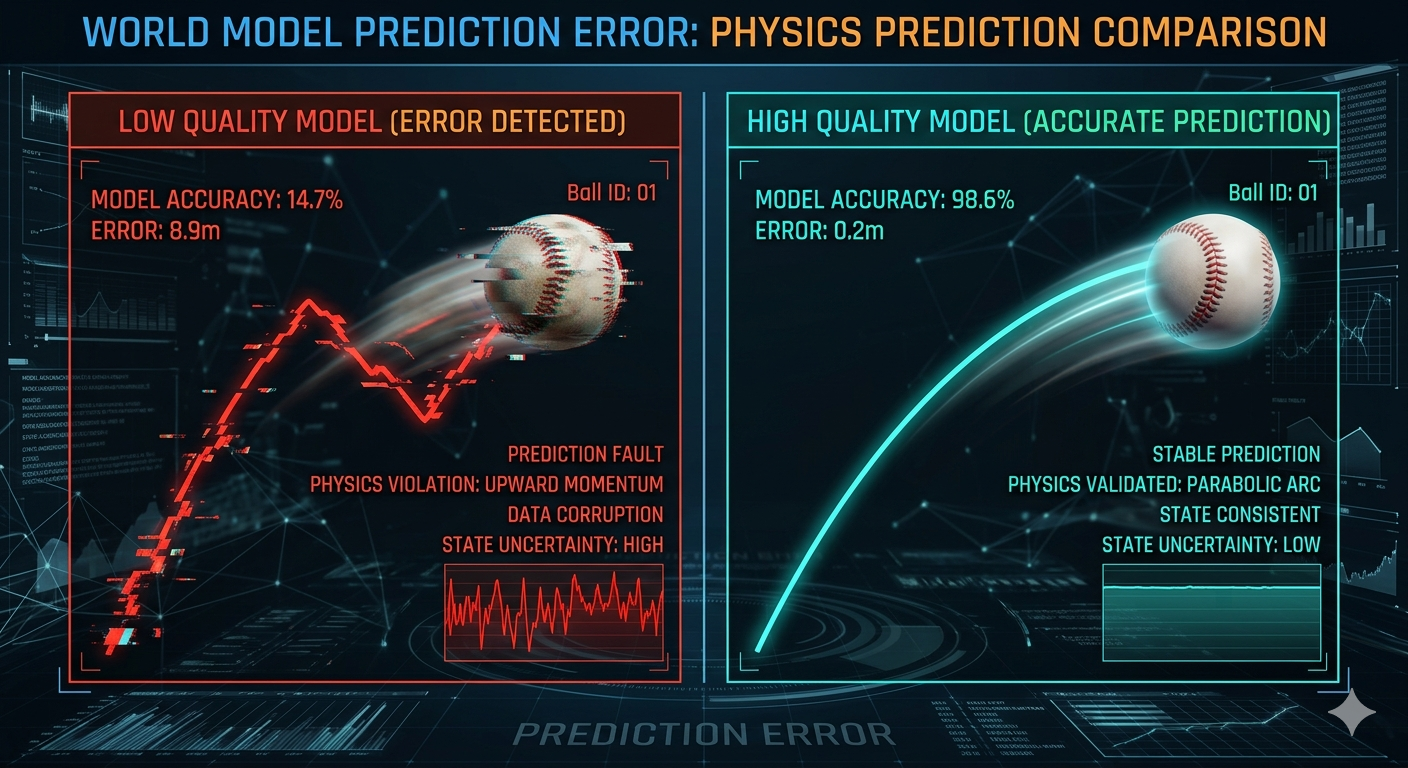
Bisherige KIs wie ChatGPT sind Meister der Sprache, aber "blind" für die Realität. Sie bewegen sich in einem Raum aus reinen Symbolen. Dieses Problem nennt man das Symbol Grounding Problem: Die KI kennt zwar das Wort "Apfel" und weiß, dass andere Wörter wie "Baum" oder "lecker" mit ihm in Verbindung stehen, aber ihr fehlt die Verbindung zum physikalischen Objekt, seiner Haptik oder wie er wirklich riecht und schmeckt.
"LLMs haben keine Ahnung, wie die Welt funktioniert. Ein Kind lernt durch reines Zuschauen mehr über Physik als eine KI in all ihren Trainingsstunden."